「ロール内異常検知」は、特定のロールにおける過去のメトリックの傾向を学習し、新しく投稿されたメトリックが、過去の傾向から外れている場合にアラートを発報する機能です。
機械学習を用いた異常検知について
システム管理者がサーバー監視に詳しい場合、監視機能を用いてサーバーのメトリックに対する静的な監視ルール(例: loadavg5が1を越えたらWarningのアラートを発報する)を設定できます。しかし、個々のメトリックに対して監視ルールを設定するのは相応の手間が必要で、定期的に調整を行わなければ不適切なアラートが発報されてしまいます。機械学習による監視を使うと、監視ルールを作ったりメンテナンスするコストを下げられます。また、サーバー監視に詳しくない場合でも、異常検知による監視が有効です。異常検知機能では機械学習を用いて過去のデータからどういったメトリックが正常/異常か学習し、新たに送られてきたメトリックが異常か自動的に判定します。異常と判定した場合にアラートを発報できます。
異常検知機能では機械学習(具体的には混合ガウス分布)を用いてメトリックが異常かどうか判定を行います。混合ガウス分布では複数のガウス分布を考慮することにより、サーバー負荷に多峰性があるようなケース(例: 平日/週末あるいは昼間/夜間でサーバーの負荷傾向が大きく異なる)でも対応できます。
ロール内異常検知によるアラートでは、該当ホストで普段と最も様子が異なるメトリックのグラフを表示します。各種通知でもこのグラフが表示されるので、障害の初期対応に活用できます(必ずしも障害の根本原因を表わしているというわけではありません)。
より詳しくロール内異常検知について知りたい場合は、以下のブログ記事をご覧ください。
ロール内異常検知による監視を設定する
監視ルール一覧画面で「監視ルールを追加」ボタンをクリックします。監視ルールの種類を選ぶ画面で「ロール内異常検知」をクリックします。
監視ルールの作成時には以下の項目を設定できます。
- 対象のロール
- 監視したいサービスおよびロールを選択してください
- 注意:1つのロールに対して複数のロール内異常検知を設定することはできません
- センシティビティ
- sensitive > normal > insensitive の順に小さな変化に反応しやすくなります。大きな変化のみアラートを発報したい場合、insensitiveを設定してください
- 監視ルール名
- 監視ルールの名前を記述してください
- 監視ルールのメモ
- 本監視ルールのメモを記述できます。この内容はアラート詳細画面やアラート通知に表示されます
- 通知の再送間隔
- アラートが発生中の間、指定した間隔で通知を再送します
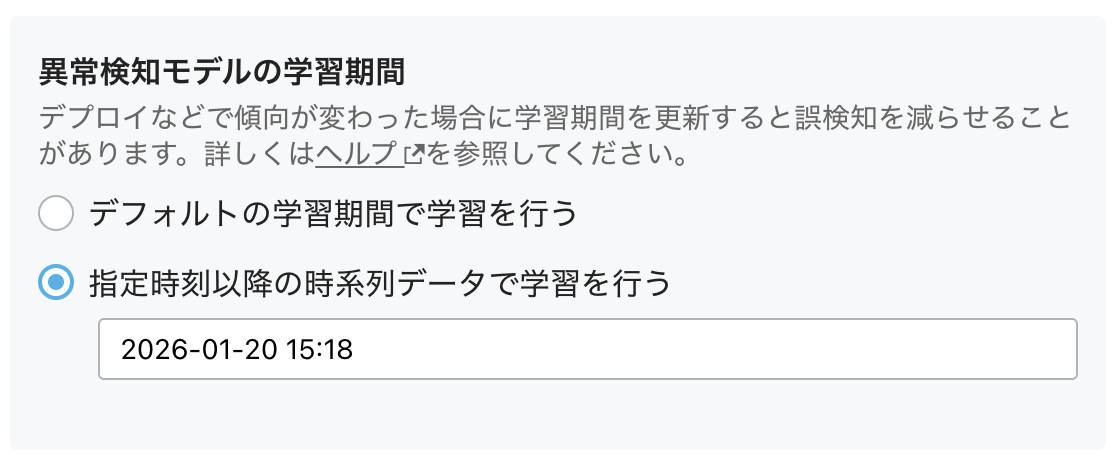
異常検知モデルの学習期間について
この項目は監視ルールの作成時には選択できず、初期状態では「デフォルトの学習期間で学習を行う」が設定されます。
監視ルール作成後の編集画面では以下から選択できます。
- デフォルトの学習期間で学習を行う
- 設定を行った日の数日後から学習が始まります
- 指定時刻以降の時系列データで学習を行う
- 指定した日時から現在までの期間を対象に学習します(即実行)
- デプロイなどでメトリックの傾向が大きく変わった場合に、デプロイ後の日付を学習期間の対象にすることで、誤検知を減らせる可能性があります
- 例:パフォーマンス改善を行ったためCPU使用率が下がった
ロール内異常検知による監視の仕様について
- Trial期間および有料プランでのみご利用いただけます
- 利用料金については、利用料金算出方法の「ロール内異常検知」の項目をご覧ください
- mackerel-agentが動作しているホストがロール内異常検知の対象となります
- Windowsホストに対しては実験的機能として提供しています。実験的機能としての提供期間中はホスト数にカウントされません
- 異常検知モデルは過去のメトリックから傾向を学習します
- 学習・判定にはmackerel-agentから収集するシステムメトリックを使用しています。カスタムメトリックやサービスメトリックは使用されません
- 監視ルールの設定以後、定期的(数日程度の周期)に学習を行います
- 初回の学習が完了するまで監視は行われません
- 監視ルール名の横のアイコンをマウスオーバーすると、現在の状態を確認できます。監視を行える状態になると、以下のような表示になります
- 過去数十日間より古い学習データは利用されなくなります
- ロール内に異なる役割のホスト(アプリケーションやデータベースなど)が含まれる場合、正しく異常を検知できない場合があります。ロール内異常検知を利用する場合は、ホストの役割ごとにロールを割り当てることを推奨します