こんにちは。Mackerelチームに所属しているエンジニアの ![]() id:lufiabb です。
id:lufiabb です。
Webアプリケーションが意図しない挙動をしたとき、ログを使って調査される方は少なくないと思います。お使いになっているログサービスの仕様にも依りますが、伝統的にはログは時間の経過に沿って並ぶので、特定のリクエストだけ調べたい場合やサービスの境界を超える場合には、調べる側で大量のログから必要な情報を抽出するためになんらかの工夫が必要になるでしょう。また、複数のサービスが協調して稼働している場合には、何がどのように連携しているのかといったシステム構成も、読む側で把握しておく必要があります。ログの1行がどこで出力されたものなのかを知るには、該当バージョンのソースコードを追う必要さえあるかもしれません。
このように、ログを出力するのは簡単だけれども、読むためには意外と多くの背景知識が必要です。なので個人的には、トレースを起点に問題の調査を行うほうが簡単だと感じます。一方で、このブログでも投稿されたメトリックやトレースの情報をどう読むのかといった観点の記事は多くありませんでした。
なので、ここではログの代わりにトレースを起点として、どうやってエラーを調査するのかを紹介します。操作の手順はMackerelを使っていますが、お使いのサービスが別のものであっても、調べ方の部分は参考になるかもしれません。
これ以降、アプリケーションにトレースを計装している前提で進めますが、まだ計装されていない場合は過去の記事等をご参照ください。
トレースでエラーが発生したと判断する条件
これ以降で実際のエラーを調査していきますが、まずはエラーの定義についてまとめておきます。Mackerelではトレースのイベント名が exception の場合にエラーとして扱います。また、以下の属性はMackerel上で特別扱いします。具体的には、この後でもみるように、追加の情報として画面に描画する等です。
- exception.message
- exception.stacktrace
- exception.type
この動作はExceptions | OpenTelemetryで記述されている仕様に沿った実装です。トレースを送る場合、上記の属性を一つずつ設定するのは面倒ですが、あらかじめOpenTelemetry SDKで専用の関数が用意されているのでそれを使うと便利でしょう。例えばGoで書くなら Span.RecordError で上記全ての条件を満たせます。他の言語でも同等の関数が用意されていると思いますが、recordException のように、言語の習慣に沿った名前となっているかもしれません。
import "go.opentelemetry.io/otel/trace" var span trace.Span ... span.RecordError(err, trace.WithStackTrace(true))
発生した課題の閲覧
上記のようにトレースを計装した状態でエラーが発生すると、Mackerelの課題一覧画面にエラーとして掲載されます。課題一覧はサイドバーから「トレース」→「課題」と選択するか、https://mackerel.io/my/tracing/issues のようなURLからアクセス可能です。
ただし、このURLは「最後に閲覧したオーガニゼーションの」課題一覧を表示するので、任意のオーガニゼーションで閲覧したい場合はMackerelのサイドバーから切り替えてください。
調査対象の概要
では調査の題材として、(本番環境ではありませんが)実際のアプリケーションで発生したエラーを調べてみようと思います。具体的には以下のエラーを調査します。
*errors.errorString: driver: bad connection
このエラーを記録したのはMackerelチームが開発しているOpenTelemetry Metricsを受信するサービスで、ソースコードは otlp.mackerelio.com で稼働しているサービスと同等のものです。そのためこのサービスでは、OpenTelemetry Collectorまたは、アプリケーションがMackerelへ直接送っている場合はOpenTelemetry SDKが主なクライアントとなっています。
課題画面の読み方
調査対象の画面を開くと色々な情報が並んでいますが、初見では何がどういう意味なのか把握しづらいかもしれませんので、各項目の意味を最初に説明します。
課題画面の上部には、エラーメッセージや発生頻度などが表示されています。
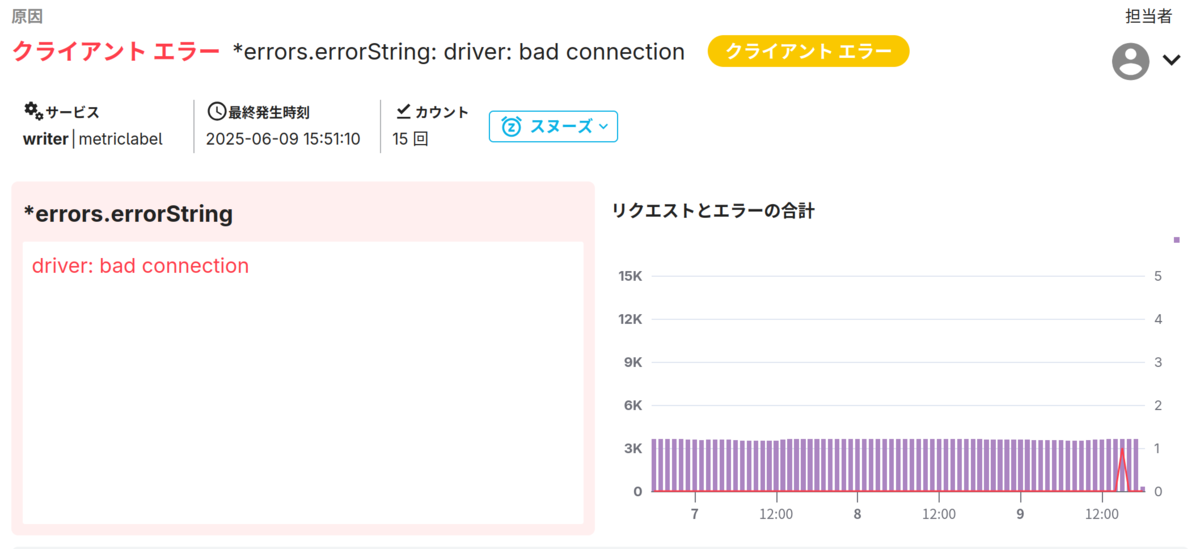
この画面からは、driver: bad connection エラーが過去に15回発生しており、直近では1回だけという状況が読み取れます。スタックトレースが存在する場合は左側に描画されますが、このエラーではスタックトレースを記録していないようですね。
そこから少し下に、トレースを扱うセクションがあります。
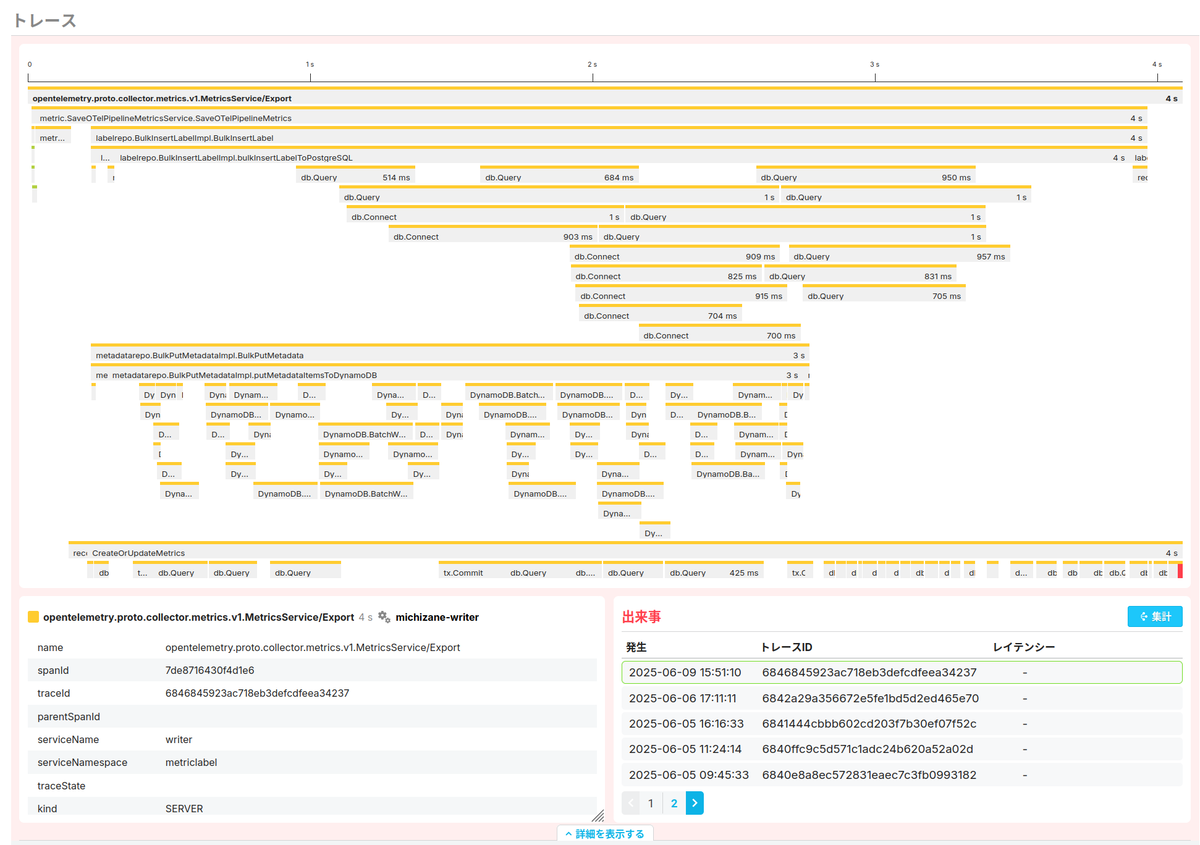
大きく3つの領域に分かれていて、上部は問題が発生したトレースのタイムラインが描画されています。横向きの線がいくつか伸びていますが、これは各スパンを意味します。このトレースではほとんどのスパンは黄色での描画となっていますが、左端を拡大すると一部のスパンは黄緑色になっています。異なる色のスパンは、別のサービスと通信をして、そのリクエスト内部で発生したイベントを意味します。
タイムラインの下は2つのカラムに分かれていますが、左下は「トレースのタイムライン部分で選択したスパンの属性」を表示しています。右下は、いま見ているエラーと同じエラーが発生したトレースをリストしています。最初に見たように、driver: bad connection エラーは過去に15回発生しているので、ここにも15個のトレースがあるはずです。
課題画面には、この他にも
- 比較するトレースを選択する領域
- 同じ時期に発生した課題
などの情報が並んでいますが、この記事では使わないので、説明は別の機会に譲ります。
どこでエラーとなったのかを調べる
画面の構成がわかったところで、まずはエラー前後にアプリケーションは何をしていたのかを調べてみましょう。
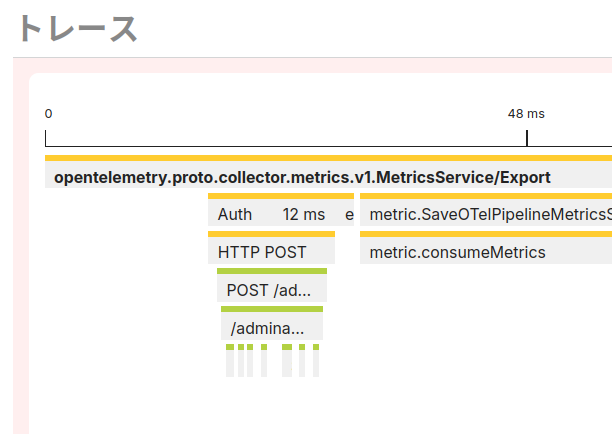
目をトレースのタイムラインに戻すと、右下に小さい赤色をしたスパンが存在していることがわかります。これがエラーの発生したスパンなのですが、このままだと小さすぎて読めないので、見たい範囲を選択して拡大してみましょう。マウス等で範囲を選択すれば、その部分だけを拡大して描画します。そうすると db.Query が20ミリ秒経過した後にエラーとなっている様子が見えますね。

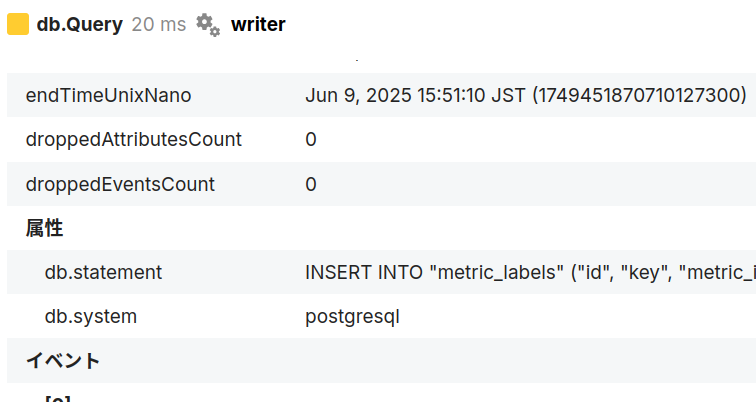
次に、db.Query がエラーになったのはわかったのですが、具体的にはどのようなクエリでエラーとなったのか知りたいところです。そこで、画面上で赤くなった db.Query のスパンを選択します。すると左下の属性リストが選択したスパンのものに変化するので、ここで見てみましょう。どうやらエラーとなったクエリは metric_labels テーブルにデータを追加しようとしたものでした。
エラーの原因を調べる
ここまでで、データベースの更新をするときにエラーとなったことはわかりましたが、それがなぜ発生したのかも調べていきます。
トレースタイムラインの左下にある属性リストには「イベント」というグループがあります。この記事の冒頭で説明した exception. ではじまる属性を付与しておくと、以下のように原因となったエラーを確認できる場合があります。
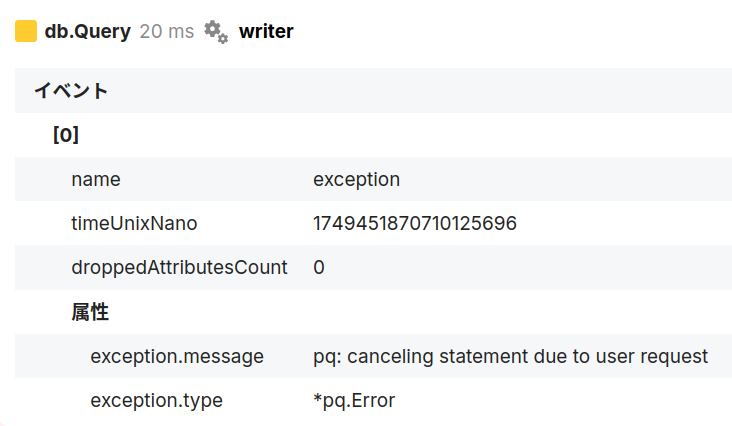
これによると、上に渡ってきたエラーは driver: bad connection でしたが、その原因は pq: canceling statement due to user request とわかりますね。Goではクライアントが切断された場合にリクエストがキャンセルされる*1ので、おそらくなんらかの理由で切断されたのだろうと推測できます。アプリケーション側の問題ではないので、障害として扱う必要はなさそうです。
根本的な理由を推測する
ここで調査を終えてもいいのですが、これは本番環境ではないにもかかわらず15件も切断が発生しているのは多い気もしますので、もう少し調べてみましょう。
トレースタイムラインの右下に、同じエラーが発生したトレースがまとめられていることは上で書きましたが、別のトレースも見てみます。そうすると、上で挙げた画像と似ていて文字が異なるだけなので画像は省略しますが、INSERT クエリが多いけれど tx.Rollback でエラーになる場合もありました。

これまでのタイムラインとはだいぶ形の違うタイムラインもあります。エラーの発生箇所は異なりますが、時間軸を見ると「キャンセルが起きるのはだいたい4秒経過した頃」という傾向があることに気付けるかもしれません。

ということで、答えを知っているので書いてしまうと、OpenTelemetry Collectorがメトリックを投稿するときのデフォルトタイムアウトは5秒なので、クライアント側がそのタイムアウトによって切断されていることが原因でした。Collectorのタイムアウトを伸ばせば解決しますが、Mackerelに投稿してくださっている全ユーザーにタイムアウトの時間を変更してもらうのは現実的ではないので、今後おそらく投稿処理のパフォーマンス改善が求められることになるでしょう。パフォーマンスを改善する際にも、影響の大きい部分から改善すると効率がいいので、対策すべき部分の特定にトレースの情報が参考になるかもしれません。
関連するログも確認したい場合
最後に、この記事ではトレースの情報だけを使って調査しましたが、情報がログにしか出力されていない場合もあると思います。こういった調査で利用するため、トレース詳細画面からCloudWatch Logs Insightsへ、あらかじめクエリを記述した状態で開くための機能があります。現時点では、クエリは以下のような形となっています*2。
fields @timestamp, @message, @logStream | filter trace_id like /(実際のトレースID)/ | limit 10000
この機能は、今のところトレース画面にしかありません。なので少し手間は増えますが、まずは属性から traceId を探してコピーします。次にトレース一覧へ遷移してから「フィルター」を開いて、「フィルター条件」でトレースIDを入力して検索します。該当のトレースが1件だけ見つかると思うので、これを開いてください。

そうすると、トレース詳細画面の右上にログへのリンクがあり、このリンクからCloudWatch Logs Insightsへ遷移できます。

上記のリンクは、トレースが内包するスパンのどれかにOpenTelemetryセマンティック規約のaws.log.group.names 属性が付与されていれば有効になるので、描画されない場合は aws.log.group.names 属性が与えられているかを確認してみてください。
おわりに
少々長くなりましたが、トレースを使って障害の調査をする手順を紹介してみました。今回はエラーを調べていますが、パフォーマンス劣化でも同じようにトレースを使って調べられるので試してみてください。また、本当に障害が起きたときは慣れている方法に頼ってしまいがちなので、事前に練習をしておくと慌てなくていいし、不足している情報にも気づくことができるのでおすすめです。