
本記事では、オブザーバビリティプラットフォームであるMackerel、特にそのAPM部分について、大規模データに対応するためにどのような工夫を行っているかを紹介します。
オブザーバビリティプラットフォームは多くのデータを処理します。 たとえば、株式会社AbemaTVではサンプリングがない場合毎秒165万スパン作成されることを先日のObservability Conference Tokyo 2025で発表しています。 また、Googleの時系列データベースであるMonarchでは毎秒数テラバイト、PinterestのGokuでは毎日4.5兆のデータポイントを取り込んでいると報告しています。 このように、オブザーバビリティ関連のデータは大規模になるものです。
私たちMackerelはSaaS型のオブザーバビリティプラットフォームを提供しており、多数の企業からオブザーバビリティ関連のデータを受け取る立場にあります。 そのために、Mackerelでは大規模データを処理するためのさまざまな工夫をしています。
本記事では、MackerelのAPM(特にOpenTelemetryのトレース)がどのようにデータを処理しているか、データ構造やアルゴリズムとあわせて、アプリケーションエンジニアをしている![]() id:mrasuが紹介します。
id:mrasuが紹介します。
要約
最初にまとめると、MackerelのAPMでは主に以下の工夫をしています。
- S3を使用し、データの可用性・耐久性を確保
- Athenaを利用し、処理を並列化
- Parquetを使用し、読み取りを効率化
- 事前集計を行い、統計処理を効率化
- ファイルを集約し、ファイル読み込み速度を改善
以降では、これらの工夫の詳細を紹介していきます。
S3、Parquet、Athenaを利用したデータ保存
まず、APMの中心となるトレースの保存方法について紹介します。
MackerelのAPMでは、トレースをS3に保存してAthenaで検索しています。 S3を利用することで、可用性と耐障害性が高まります。 また、Athenaを利用することでクエリエンジンの運用コストを減らしつつ、広範囲のデータを並列に処理できるようにしています。
しかし、ただS3に保存してAthenaを使うだけでは検索が遅くなってしまいます。 この問題に対するトレースの保存方法の工夫を説明していきます。
1. パーティションを利用した効率化
MackerelのAPMでは、テナントと時間でパーティションを分けています。
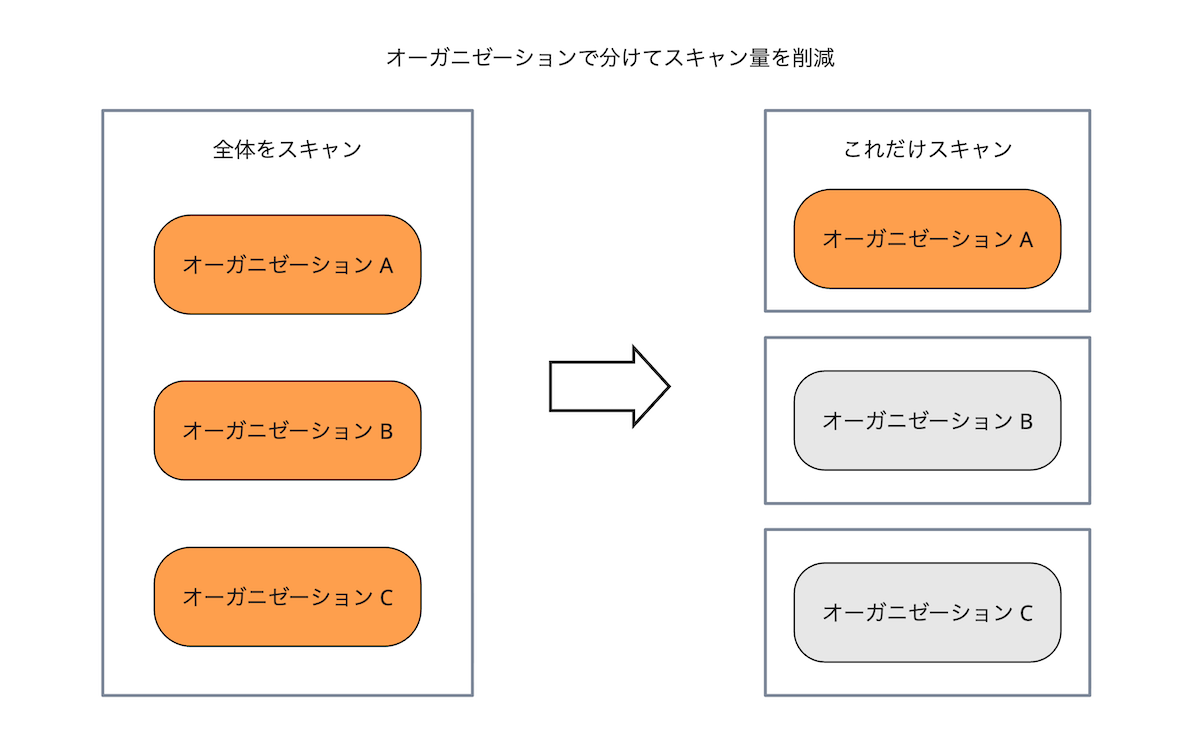
MackerelはSaaSであり、複数企業が利用する、マルチテナントです。 テナント(Mackerelのオーガニゼーションに相当します)によって、大量にトレースを送る場合も、少量のトレースで済む場合もあります。 そのため、データ量はオーガニゼーションによって大きく変わります。 しかも、複数オーガニゼーションのデータを同時に参照する必要はありません(リスクですらあります)。
そこで、他のオーガニゼーションの影響を減らすために、トレースを保存する場所をディレクトリ(キー)ごと分けています。 Athenaでも、パーティションを使ってオーガニゼーション単位でファイルを参照できるようにすることで、検索時に他のオーガニゼーションのデータが影響を与えないようにしています。
さらに、時間でもパーティションを分けています。
オブザーバビリティに関する特徴のひとつに、「最近のデータを検索する頻度が高い」というものがあります。 たとえば、障害に対応しているときは、障害が起きている期間を中心に検索するでしょう。 この特徴を考えると、検索のたびにすべての期間のデータをチェックする必要はありません。
つまり、期間ごとにファイルを分けてしまえば、最近のデータがあるファイル群を作ることができます。 これをAthenaで実現するために使用するのが、「時間」でのパーティションです。 時間ごとにディレクトリを分けることで、内容を確認する必要のないファイルをAthenaのスキャン対象から除外できます。
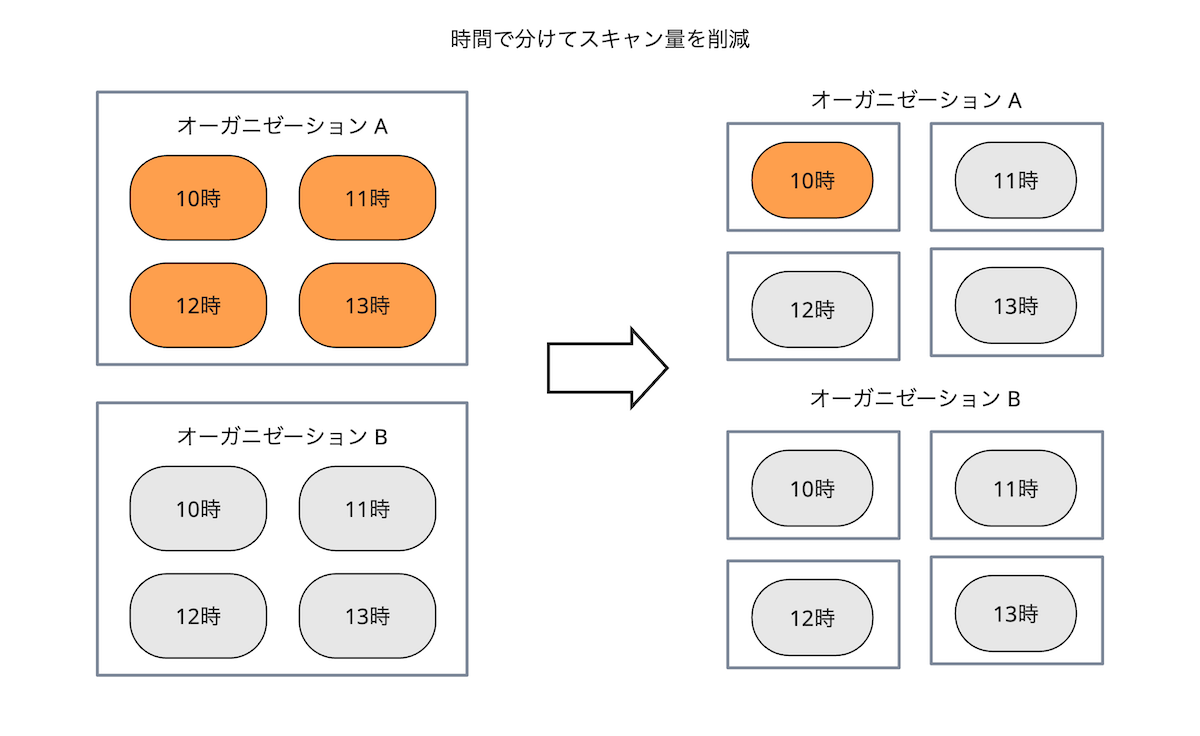
Athenaではスキャン量が実行時間に直結するので、パーティションを活用すると実行時間を削減できるわけです。
2. Parquetでの効率化
Parquetを利用することで、さらにAthenaを効率化します。
検索をするとき、ファイルにあるすべての情報を利用することはあまりありません。 たとえば、遅いトレースを探しているとき、実行されたSQLやHTTPのパラメータが必要になることは少ないでしょう。
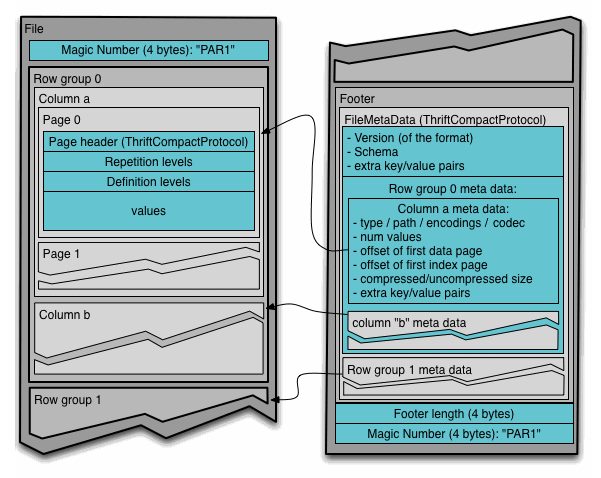
つまり、必要なデータがファイル内で固まって配置されていれば、スキャン量やシークが減って速くなります。 そのために利用しているのが、列指向フォーマットであるParquetです。 Parquetは列単位でデータが並んでいるので、検索や集計を効率的に実行できます。
具体的には、下図のように列ごとにデータが並べられています。
3. 専用の列を作って効率化
さらに、MackerelのAPMにはHTTPサーバー画面やデータベース画面がありますが、HTTPやデータベースの情報(トレースでは属性として記録されている値)は特によく検索されます。 このような、頻繁に検索される属性のための特別な列も作成しています。
OpenTelemetryが持つ「属性」は辞書形式で情報を保有するため、属性の値を検索するためにはすべての属性を走査する必要があります。 しかしそれでは時間がかかるので、特によく使われる属性には専用の列を作っています。 たとえば、HTTPのパスを表す属性のための専用の列を作ることで、特定のパスを使うトレースを素早く発見できます。

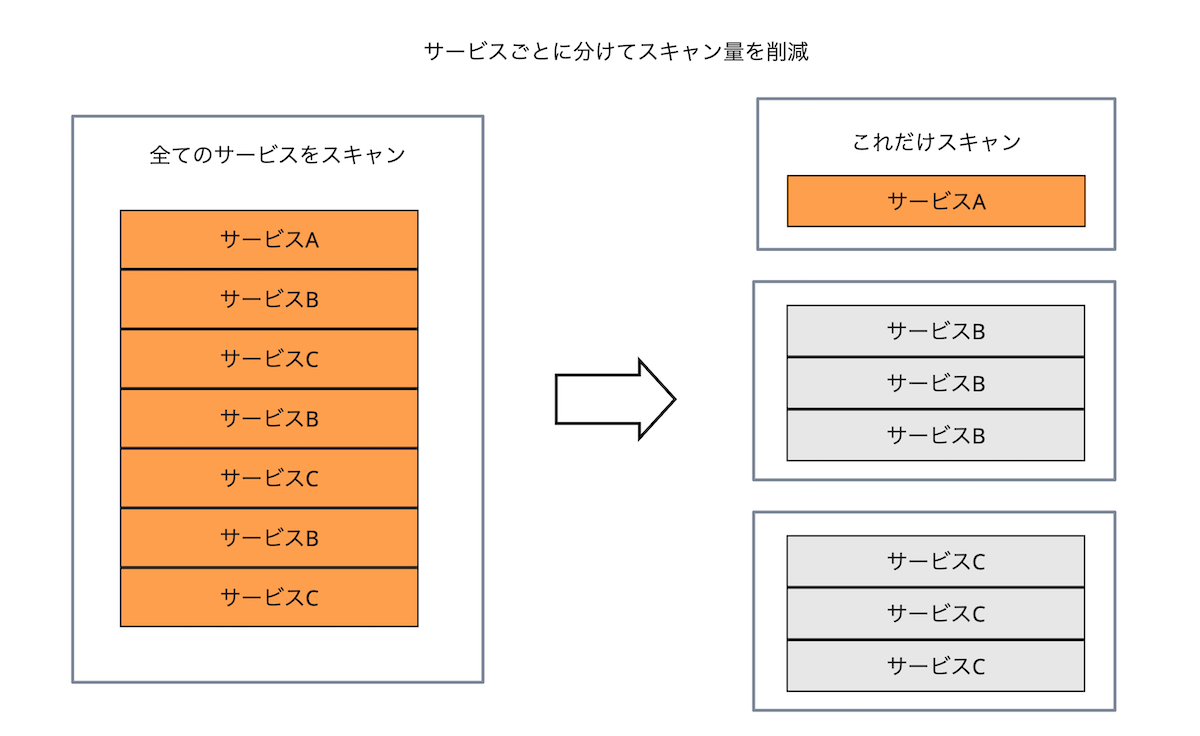
4. サービスごとに分割して効率化
検索対象の偏りはまだあります。 「サービス」です。
マイクロサービスに限らず、複数のコンポーネントが動いているアプリケーションは珍しくありません。 そして、サービスにはトレースの量の偏りが大きいため、ノイジーネイバーならぬノイジーサービスが問題になります。
これに対応して、サービスごとに行グループを分割しています。 分割することで、特定のサービスのみを読み込めるようになっています。
事前集計による統計処理の効率化
MackerelのAPMにはデータベースクエリやHTTPリクエストの統計を表示する機能があり、レイテンシーの最大値や95パーセンタイル(P95)を表示しています。 しかし、毎回データを集計するのは大変なので、定期的に集計をしています。 たとえば、データベース画面では合計実行時間や、95パーセンタイル、実行回数などを表示しています。
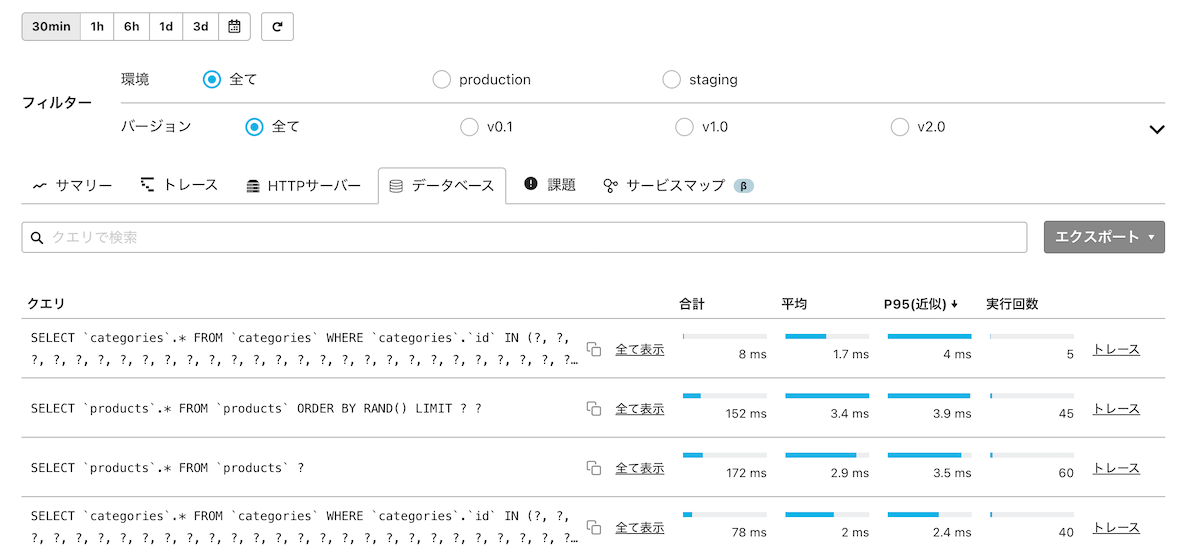
これらの値を表示するために定期的に集計を行い、集計済みの期間と未集計期間の値を合算しています。 さて、合計実行時間や実行回数であれば合算は簡単ですが、95パーセンタイルを求めるには全体をソートする必要があり、事前の集計が効きません。 これを解決するために使用しているのが、t-digestです。
t-digestとは、簡単に言えば「パーセンタイルの近似値を出せる」データ構造兼アルゴリズムです。 しかも、分割して処理した結果を合算すると全体のパーセンタイルを出せます。
この性質は非常に便利で、AthenaやTrino、Apache Pinotなど多くのソフトウェアでパーセンタイルを計算するために利用されています。 一般的には「子ノードで計算したものを親ノードで合算してパーセンタイルを出す」というように使われますが、計算途中のt-digestを取り出せば、パーセンタイルの導出を遅延させることもできます。
この性質を使って、合計実行時間などと同じように、事前に計算したt-digestとオンデマンドで計算した未集計部分のt-digestを合算しています。 こうすることで、任意の集計期間のパーセンタイルを導出できます。
ファイル集約による読み込み速度の改善
さらに、ファイル数を減らす工夫もしています。
APMではトレースをリアルタイムに把握するため、頻繁にトレースを取り込んでいます。 結果、取り込み結果としてのファイル数も多くなります。
そうすると発生するのが、いわゆる小ファイル問題(small files problem)です。 これは、ファイル数が多いせいで「読み取りのオーバーヘッドが大きくなる」「効率的な処理ができなくなる」などの問題が発生することを指した言葉です。 S3とAthenaを使っている場合、「API料金が高くなる」「GETの回数制限に引っかかってAthenaの処理が遅くなる」というような問題も出てきます。
これらの問題を回避するため、MackerelのAPMでは定期的に複数のファイルを1つのファイルにまとめています。
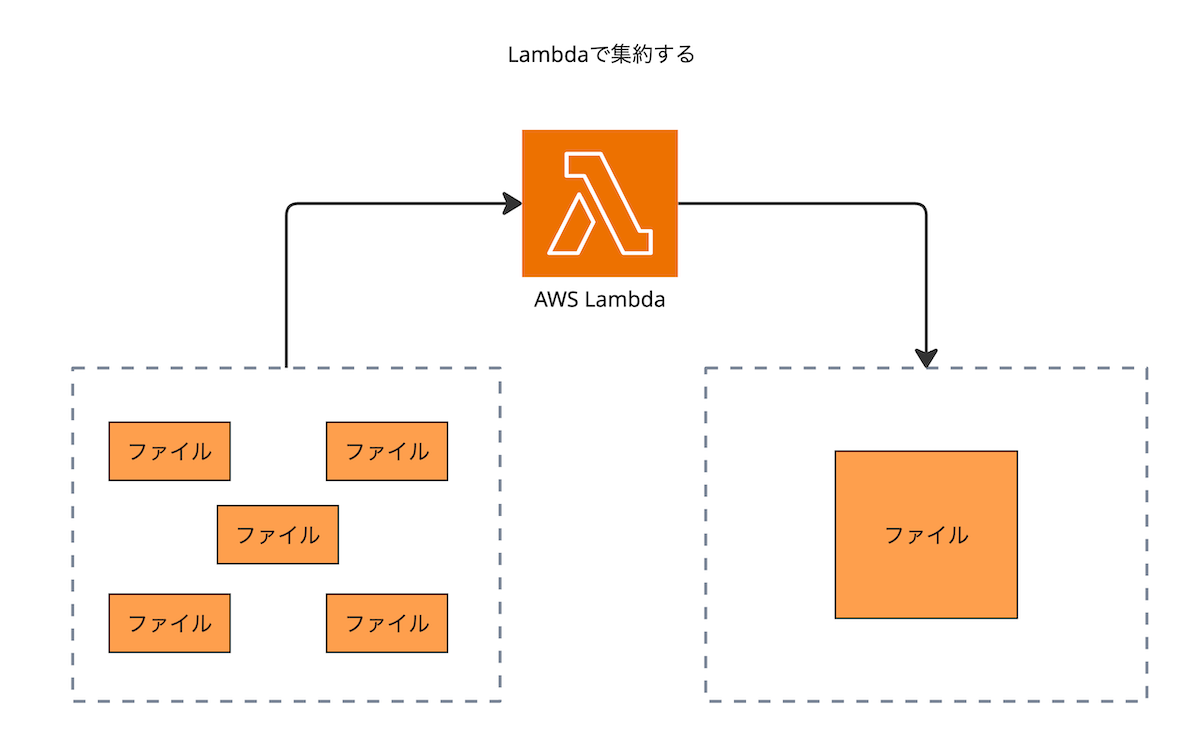
ただ、ファイルを集約する処理は、通常の取り込み処理よりもはるかに負荷がかかる処理です。 また、常時実行しているものでもありません。 そのため、集約処理は下図のようにLambdaで行っています。
さらに、S3にはトランザクションがないため、「集約したファイルを追加しつつ、元のファイルは削除」という処理を原子的に行うことはできません。 つまり、ファイルを追加したあとに元ファイルを削除すると、Athenaが集約前と集約後のファイル両方を参照してしまう可能性があります。
これを回避するため、集約前のファイル群だけを参照するテーブルと、集約後のファイル群だけを参照するテーブルを用意しています。
これで、集約前後のデータが混ざらず、安全にファイルを参照できるようになるわけです。
おわりに
以上、MackerelのAPMで行っている工夫を紹介してきました。
さらに、先日行われたhatena.go #2では実装に焦点を当てた発表をいたしました。 本記事では俯瞰した工夫の紹介をしましたが、hatena.goではより詳細な話をしているので、スライドや動画もぜひご覧ください。
もう「なんか遅い」で悩まない!開発者のためのAPM入門

アプリケーションを開発・運用していると、特定の処理が遅い、リクエストごとに応答時間がばらつくなど、「なんか遅い」と感じる場面があります。本資料では、こうした「なんか遅い」と感じる状況に対して、どこから調べればよいのか、何を手がかりにすればよいのかという観点から、APM(アプリケーションパフォーマンスモニタリング)が調査の進め方をどう変えるのかを解説します。