
Credit Saison Co., Ltd.
Credit cards, leasing, finance, real estate and more
 Nulab Inc.
http://nulab-inc.com/
Nulab Inc.
http://nulab-inc.com/
Date of publication: October 15, 2014 · All information contained herein is accurate as of when this interview took place.
Let's begin with some brief self introductions.
Tanaka
My name is Shinji Tanaka( id:stanaka / @stanaka)and I'm the CTO at Hatena. Since Mackerel has now been officially released, I came to chat with the folks from Nulab, who have been users of our service since its inception.
id:stanaka / @stanaka)and I'm the CTO at Hatena. Since Mackerel has now been officially released, I came to chat with the folks from Nulab, who have been users of our service since its inception.
Mackerel: A Revolutionary New Kind of Application Performance Management 
Someda
My name is Takashi Someda( id:tksmd / @tksmd)and I'm the technology evangelist for Nulab. I'll be participating today remotely from our Kyoto office.
id:tksmd / @tksmd)and I'm the technology evangelist for Nulab. I'll be participating today remotely from our Kyoto office.
Nakamura
I'm Tomonari Nakamura( id:ikikko / @ikikko)and I'm an engineer at Nulab. I focus mainly on Backlog, our project management tool, but I also oversee some aspects of our infrastructure. I helped Nulab deploy Mackerel and set it up.
id:ikikko / @ikikko)and I'm an engineer at Nulab. I focus mainly on Backlog, our project management tool, but I also oversee some aspects of our infrastructure. I helped Nulab deploy Mackerel and set it up.
Fun. Creative. Collaboration. | Nulab Inc. 
Backlog - Project management tool for everyone in the team. 

What was the story behind Nulab's deploying Mackerel?
Someda We were developing and running Cacoo, which lets you create diagrams online, and Backlog, a project management service, with a relatively small team. Then around fall of 2013 we added a few more services -- Typetalk, a chat service, along with Nulab Account, a single sign-on service for all Nulab applications. Before we knew it, our suite of services had doubled! (laughs) Managing our infrastructure and monitoring started to become real issues. I'm sure readers who maintain their own in-house services will know what I'm talking about -- setting up and managing a monitoring workflow is time-consuming. We wanted a solution that matched the way we ran our services, so we tried Hatena's Mackerel.
Tanaka At the end of 2013, I approached Nulab -- "We're thinking about this new service called Mackerel. Would you be interested?" It was good timing, because Nulab was right in the midst of what Mr. Someda has just explained. They were even more onboard with the concept than I expected. Since that time, we've gotten a lot of feedback from them on the product. Having active users early on in the development stage is a huge point of reassurance for developers.
Someda This might be part of the Nulab culture, but a lot of our team are proactive about diving into new services and development frameworks. Mr. Nakamura, too, started using tools like Vagrant two or three years ago, and has done quite a bit of testing on how to improve our infrastructure, such as finding ways to make testing and building easier. Our new Typetalk service uses AngularJS and other newly-trending technologies.
Someda The fact that Mr. Tanaka and I had both been in Kyoto back in the day was one of the factors behind Nulab's becoming an early user of Mackerel. We would often borrow seminar rooms at Hatena's Kyoto headquarters and hold workshops on AWS and Flex, and so on, so you could say we were well acquainted within the developer community.
Nakamura Mr. Someda, another team member who looks after our infrastructure, and I were the ones involved in incorporating Mackerel.
Someda We gradually phased it in in steps. Rather than using it from the get-go for our production environment, we tried using it to monitor our development environment for new services. At first, one of our big fears was of the monitoring agent bugging out and wrecking our production environment. So we wanted to roll it out in stages -- we reasoned that our newly started services wouldn't have sudden spikes, so we deployed the agent on part of our new services and watched its progress. Once we established that it posed no harm, we started bringing it onboard more of our services. All the same, we actually wound up deploying Mackerel in our production environment very early on.

Tanaka Deploying a new tool in a production environment poses risks, so I'm very grateful to Nulab for making that bold move. At Hatena, we've also been using Mackerel for monitoring in our production environment.
What are some of the things that attracted you to Mackerel?
Nakamura The monitoring tool we were using previously was becoming a strain to manage. Each setup individually was nothing major, but as we used the tool on more of our machines, maintaining and operating them all started to become increasingly difficult. We wanted to manage everything in a stroke without wasting time. Timing-wise, we had just reached four total services, and we were getting to a point where we didn't have the manpower to watch our entire infrastructure. We wanted something that would let each person in charge of a different service maintain it freely, so we turned to Mackerel as an external service.
Someda Until then, we used Munin as our monitoring tool. This tool is written in Perl, but it has a lot of dependencies, so you have to install many other libraries first. As we upgraded our agents, changed from 32-bit to 64-bit, and our environment evolved, maintaining everything in balance and keeping the dependencies up to date was eating up all our time. Also, Munin generates graphs server-side, so the more machines you have polling for graphs, the more it draws a load on the Munin server and makes graph generation slower. So even though "Munin server management" had nothing to do with our actual work, it was eating up a huge amount of time and becoming a job in its own right. Mackerel, on the other hand, is written in Go, and it has no dependencies to worry about. Nor do you have to maintain a server. The stress of having multiple environments play nicely together was gone.

Tanaka We used Go for the Mackerel agent in order to minimize dependency issues, so what Mr. Someda describes is exactly what we had hoped for. At Hatena, we had the same issue: we were expending costs on server tools. However, we realized this could be made more standardized among companies -- it seemed like a waste to have each firm bearing the costs of monitoring its own servers. This is an established trend in the Internet services industry: focus on your core services and outsource the remainder. The Slack chat tool and the use of repositories like GitHub are part of this move towards outsourcing. In the past, you would manage tickets on Redmine, but now the move is to use external services. It's also becoming more and more common to adopt a speedy approach to development: build a team to develop a service, and if it doesn't pan out, scrap it immediately. If you build all of your tools in-house, though, you start to eat up time on launching and then scrapping these in succession. Today, needs are changing -- you procure the tools you can externally, focus on your own service, and opt out of tools as soon as they become irrelevant to your needs. Just as AWS(Amazon Web Services is used for infrastructure because it meets the industry's more fluidly-changing needs, tools are also increasingly being sourced externally.
Someda I definitely agree with you in terms of AWS and cloud services being a common sense thing today. That culture is what was pushing us in this direction. One reason we liked Mackerel is because we wanted to improve our maneuverability. Four years ago, we moved all of our server infrastructure off to AWS. We have virtually no servers on-premises anymore.
Nakamura We do have one mail server, though.
Someda One recent change today is that, when something goes wrong, you just swap in a server wholesale. To use a recent term, we would call this immutable infrastructure. We use Ansible to manage our server builds, and when there's an issue, we easily just drop in a new server. In terms of monitoring, we want to keep the same level of service even as we change something about our server. For example, if we change an instance type on AWS for a new one, we want to monitor it to see if the load changed or if the service level has remained the same. Tools that monitor a host, however, lose that data when the host changes. With Mackerel, you can poll data in a role-based fashion. Mr. Tanaka first explained to us the potential benefits of this approach; once we tried it ourselves, it really stuck. We can see at a glance what happens when we deploy a certain instance type. Everything is much clearer now.
Tanaka At Hatena, we always thought it might be interesting to approach server management through the idea of roles. We played around with the concept on our in-house monitoring tools and really liked what we saw. The term immutable infrastructure was starting to be thrown around in 2013, so the idea of role-based monitoring happened to coincide perfectly with this newly emerging need. With Mackerel, you can see continuous graphs before and after you change your instance type on AWS. I believe this is the first monitoring tool of this type. Existing monitoring tools weren't built around this concept of managing an immutable infrastructure, so they fell short in that respect.

Could you tell us a bit more about how immutable infrastructures and monitoring work together?
Tanaka The easiest example is auto scaling. So, for instance, if servers are increasing or decreasing in number within a 24 hour period, how do you handle monitoring? This is something I heard from another company, but before, as a solution to that problem they would keep one server and observe and monitor just that one in place of all the others. So people were visualizing server performance through these kinds of bad practices or workarounds.
Nakamura It's a lot easier today to maintain an immutable infrastructure. I think the fact that AWS is widespread now played a big part in this. At Nulab, we used to have a policy to not increase our number of servers. It takes time to launch a new one, so we tried to keep everything contained within a single server. When you're doing that, opting for an immutable approach is impossible. By moving to AWS, you deploy a server setup with built-in redundancy. This way, there's not much need to monitor the up or down state of a single host. Instead, it becomes key to visualize server performance in terms of roles. With the old approach, a server going down was a major issue; today, you run your service on, say, ten hosts on AWS, so if one goes down, your service stays online with the remaining nine.
Someda As we moved to AWS, the approach to host configuration was also changing. It used to be that keeping everything self-contained on a single server was considered more cost-effective. However, managing your server build this way is very difficult. With AWS, server restarts from physical damage and the like happen as a matter of course -- having your whole service go down because of a single host is pretty rough. A role-based approach to server management is a natural extension of this trend, and the role played by a single host is constrained to smaller parameters.
Tanaka Ideally, you wouldn't even think about or be actively conscious of how many machines you have dedicated to a specific role. So for instance, just having graphs that show aggregate CPU usage or overall capacity grouped by role should be enough.
Was there anything specific that triggered your switch to AWS?
Nakamura The biggest reason has to do with the requirements our services call for. For example, Backlog requires increasing and decreasing disk capacity on an ad-hoc basis. With traditional hosting, it takes time to expand disk capacity. Plus, we wanted to use all of our resources flexibly without concerns like storage space. This makes a cloud-based approach much better than hosting. On the other hand though, there may be cases where, if flexibly scaling is not needed, a host-based infrastructure may be the better approach in terms of cost and ease of management.
Tanaka Mackerel can also be used in a hosting environment, but honestly it really shows what it's capable of in a cloud architecture. I highly recommend it for those who really want to leverage the potential of the cloud.
Someda One of the big factors that pushed Nulab to switch to AWS was the existence of the Amazon CloudFront CDN. Until that came out, there weren't really any CDNs that suited the scale we needed. Cacoo's editor runs in Flash, so we wanted to cache that data. When you're pushing it from Japan to a server in the US, though, the latency is no joke. We have a lot of users overseas, so the fact that AWS has data centers in North America is huge.
Does Mackerel let you monitor systems that span multiple regions, such as Japan and North America?
Tanaka It's no problem. So long as you're online, it doesn't matter if the destination is on the other side of the Pacific. After all, millisecond-level latency isn't really an issue for monitoring.
Nakamura One thing I like is the sense of timing with alerts. With Munin, alerts were on a five minute basis. Mackerel's are on a one minute basis -- and we were able to track down an issue that was too hard to detect in five minute increments. By the way, the issue was that the CPU usage spiked right when Munin would draw its graphs (laughs).

Someda One minute increments may seem insignificant in terms of timing, but we found when we actually used this feature it made a big difference.
Nakamura Five minute intervals are fine if you just want to get an overall sense of trend within your hosts, but if you want to see exactly how resource consumption is spiking, shorter intervals are much better.
Someda There are, of course, trade-offs. Now you suddenly have a lot more data you have to look at. Sometimes this can pose a bottleneck for the agent.
What about those engineers out there who may prefer monitoring on an individual basis?
Nakamura It's important to consider what it is you're trying to provide. Keeping everything in a 100% perfect balance using human resources is not practical. Once you consider what it is you want to provide in-house, you can outsource the rest to external services.
Tanaka When you're managing server operations and handling infrastructural improvements in-house, as an engineer, it feels like you're doing something meaningful, but it bears keeping in mind that this does not actually contribute to creating the real value of the service you set out make. Once you are using outside services to handle maintenance, engineers start having more time to focus on building your core services and getting real work done. I definitely recommend using external tools, especially for those who are running small companies. (laughs)
Someda Mackerel's API also lets you define the metrics you want. I think this is a pretty big deal. For instance, our services run on Java, so we want to check performance on JVM (Java Virtual Machines). If one host suddenly spikes to full activity over GC (garbage collection), we want to know if all of our application servers are spiking, or if just one server peaked. Also, this rarely happens, but there could even be a case where something is drawing images and it kills the JVM. (laughs) With monitoring, you can finally figure out if it's a specific bug that segfaults the app, if it's something system-wide, or what.
Tanaka When you're using these tools every day, you have to pay close attention the little details. Monitoring, in particular, can be relatively attention demanding. A lot of the open-source monitoring tools were built around the early 2000s, and were designed around monitoring by host, not role, which is why the architecture of those is out of date.
Someda Many of them also have clunky UIs.
Nakamura I like the fact that Mackerel's UI lets you layer graphs -- this is convenient. You might not understand a trend when you look at output from a single host, but when you see it stacked up against other servers, you can quickly spot if there's a global trend or if one host is spiking, and you can catch all of this at a glance.
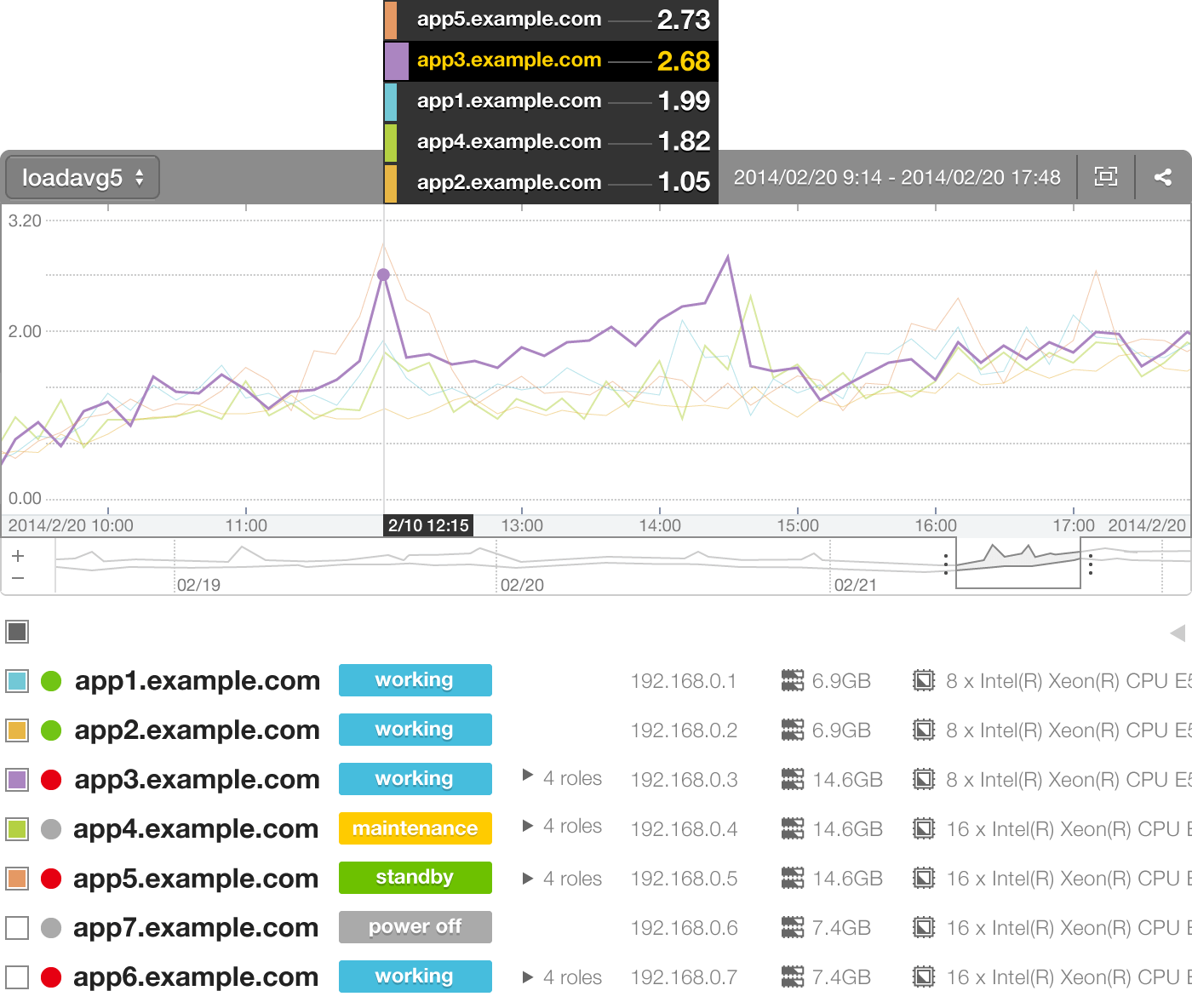
Someda The graphs are really well put together. Troubleshooting is stress-free -- we can go in and look at a weekly view, then drill down by hours until we find exactly when a specific problem popped up.
Tanaka We put a lot of effort into the graphing function. Actually, we used Google Finance's graphs as a point of reference. We thought, "Man, it'd be great if you could visualize server performance with graphs like these!" (laughs) Since this is a paid-for service, we knew usability and an intuitive UI were crucial, so we really fine-tuned it. We zoomed in on a lot of things we considered key: being able to select a specific monitoring period, being able to toggle between tiered and stacked graphs, switching between CPU and memory readouts, and so on. Mackerel was built with the needs of infrastructure managers in mind. Although it was originally based on our own needs in-house at Hatena, we didn't know to what extent our needs spoke for others' needs, so getting outside feedback from Nulab was a huge help.
Nulab, did you feel there was any advantage to being an early user?
Nakamura Yes. It was really great being able to easily communicate our needs. Over time, several of these were actually incorporated as new features.
Tanaka For example, one function lets you switch between a week, month, and day view with a single button. This was based on one of Nulab's requests.
Nakamura Since we were using Mackerel since well before beta, it did take a bit of time to get it up and running at first.
Tanaka The early versions had no documentation, so we were really grateful for Nulab's literacy in this area. They saw that logs were stored in JSON format, so they came back and said, "Do you want data as JSON files?"
Nakamura I mentioned earlier that our biggest fear going in was it wreaking havoc on our production infrastructure. However, there were no issues with our actual service, so we were able to use Mackerel without worrying.
Do you plan to keep using Mackerel at Nulab?
Nakamura We do plan to keep using it.
Someda We're so used to Mackerel now, I can't imagine being told to do without it. (laughs) It'd be tough.
Tanaka I'm happy to hear that! (laughs) We really appreciate your ongoing support.

We asked our users how they use Mackerel.
Credit cards, leasing, finance, real estate and more

MaaS enterprise for highway buses / railways and mobile portal site operation

Media, Internet Advertising, Game, and Investment Development Business

Providing cloud services well-suited for businesses

Design, development, and operation of online games and digital services

Offering a variety of internet services targeted at consumers

Services promoting collaboration across the globe
Get started with a free trial and experience all the features Mackerel has to offer. To learn more about volume discounts, please contact us using this form.
If you read this whole interview, we'd like to say thanks by offering a 1 week extension on your free trial. Contact sales with the name of the organization you'd like the extension for.